Full Template
This feature is only available in paid plans. Learn More
The AI Assistant can generate or restyle an entire template in a single turn — not just a row, content block, or text selection. This is the heaviest design-quality work the assistant does, but also the easiest and most powerful path for a user to go from a blank canvas (or an existing template that needs a full overhaul) to a finished design.
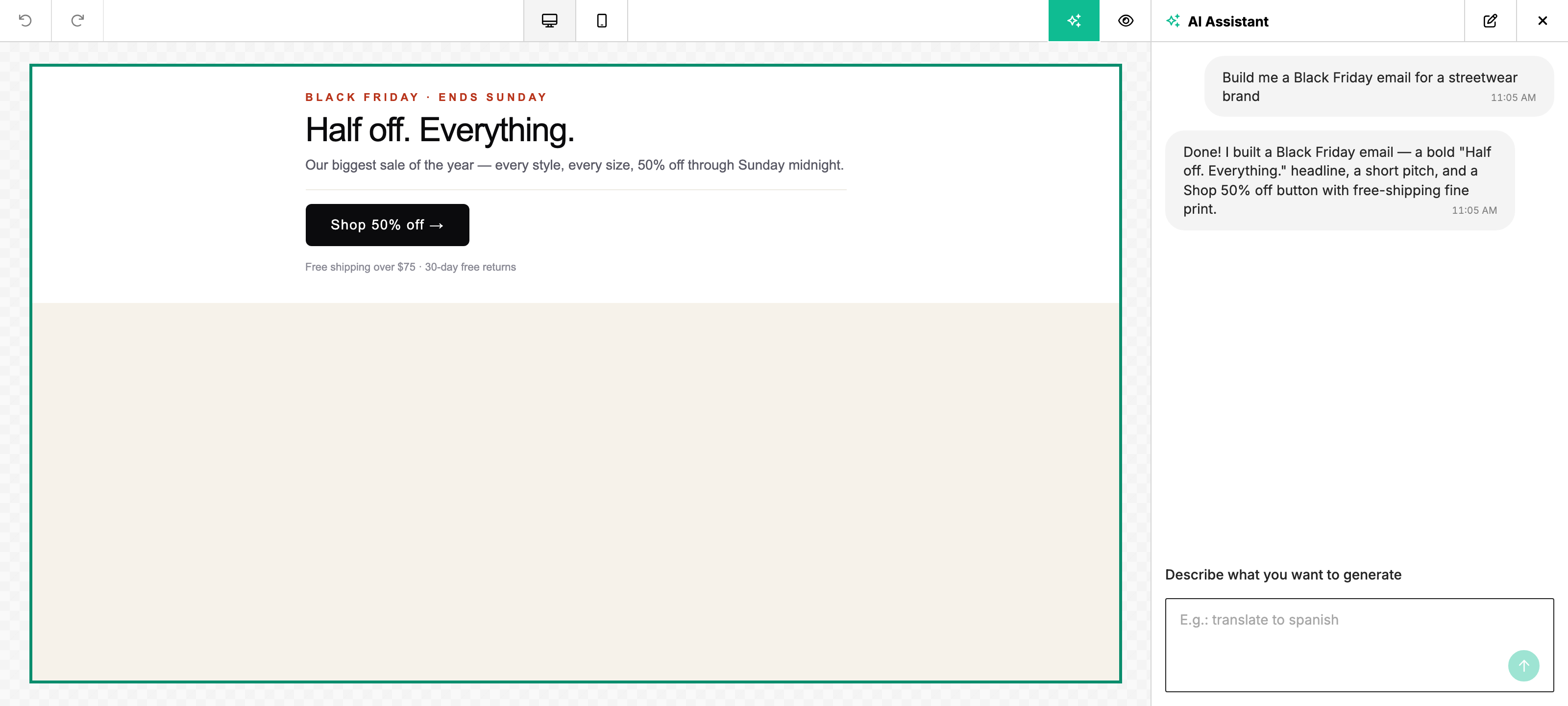
When it shines
- Starting a new template from scratch — "build me a Black Friday email for a streetwear brand, dark mode, with a hero, three-column product grid, and a footer" → the assistant produces the whole layout in one shot.
- Restyling an existing template — "keep the same content but switch this from a casual newsletter to a corporate enterprise tone" → multi-row restyle in a single turn.
- Bulk content + layout edits — anything that touches the body as a whole (translating an entire email, swapping the brand voice, regenerating around a new product).
Tradeoffs
Full template generation does more work than a per-block edit, and that shows up as:
- Slower. A full template turn typically takes tens of seconds (sometimes longer for very large designs), versus a few seconds for a single content rewrite. The assistant has to reason over the whole layout, propose a structure, and emit a much larger payload.
- More credits per turn. A full-template turn consumes meaningfully more credits than a per-element edit (see Pricing).
- More moving parts. The pipeline has more steps — schema validation, multi-step planning, larger context windows. That means more surface for transient provider hiccups; the automatic fallback chain handles most of these silently.
For users iterating on a single block or paragraph, per-element edits are almost always the better answer — they're faster, cheaper, and more predictable.
Disabling full template generation
If the cost or latency profile doesn't fit your product — or you want to keep the assistant available for fine-grained edits while removing the heavyweight option — set features.ai.fullTemplateGeneration to false in unlayer.init:
unlayer.init({
features: {
ai: {
enabled: true,
assistant: true,
fullTemplateGeneration: false,
},
},
});
When disabled:
- The template-level "generate" affordance disappears from the editor.
- Row, header, footer, content-block, and text-level edits remain fully available.
You can also vary it per surface — turn it on in a power-user editor but off on a customer-facing embed where cost predictability matters more — by passing different features.ai.fullTemplateGeneration values to each unlayer.init call.
The HTML / screenshot import flow (a console-only feature today — see AI Template Importer) always produces a full template. The init flag described above only affects the editor — it doesn't reach the import API. To disable imports specifically, contact your Unlayer account manager.
Why disable it?
The most common reason is cost predictability. Full template generations have the largest per-request credit cost on the platform, so a project that opens the assistant up to non-power users may want to cap usage to the cheaper, faster per-element flows. Other reasons embedders cite:
- Latency budget — keeping every AI turn under a few seconds for a snappier UX.
- Output consistency — per-element edits respect the existing design more tightly; full generations re-author large parts of the layout.
- Plan tier gating — exposing full template generation only to higher-tier customers, while keeping the per-element assistant on every paid plan.
Default behavior
When the AI Assistant is on, full template generation is enabled by default — no extra flag needed. You only need to set features.ai.fullTemplateGeneration if you specifically want to turn it off while keeping the rest of the assistant available.
Related
- Row — narrower scope when full-template is overkill.
- Text — single-block edits for text, button, and heading tools.
- Pricing — credit cost per request type.
- Picking a Model — pinning a frontier model amplifies both the upside and the cost of full template generation.
- Full vs Simple schemas — the assistant reads and writes the compact Simple form of the design JSON; the editor converts to and from the Full form around each turn (the schema-validation step in the pipeline above).
- Events & Callbacks —
ai:assistant:on:successreports the per-turn duration so you can see how much wall-clock time a full template turn costs.